
今回は、Hadoopを中心としてビッグデータ分析に関わる情報のさわりみたいな部分を解説します。
Hadoopとは
Hadoopは分散処理技術を扱ったソフトウェアであり、大規模・大量データの蓄積(HDFS)と並列分散処理(MapReduce)による高速なデータ処理ために利用する技術です。
HDFS:Hadoop Distributed File Systemの略
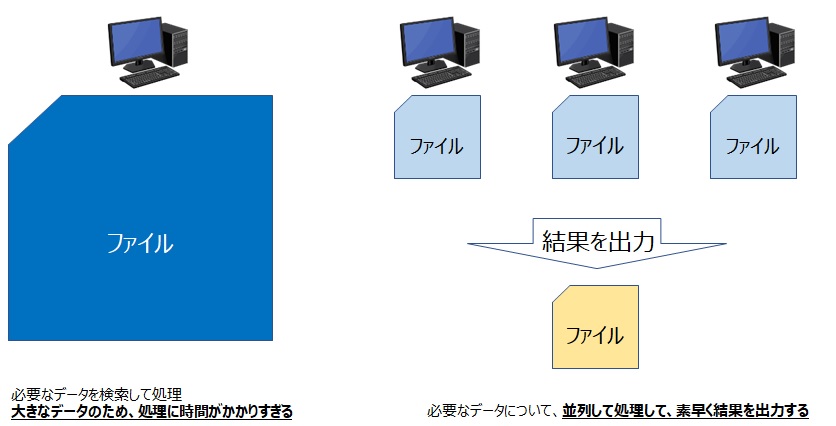
1台のコンピュータで大規模なデータを処理すると時間がかかりすぎるため、コンピュータをたくさん並べて高速に処理することを目的に利用します。
Hadoopは歴史的に1系、2系、3系とバージョンが上がっています。
Hadoopは、Apache Hadoopと呼ばれるOSS製品のため、誰でも無料で自由に構築することができます。
Hadoopの仕組み
Hadoop1系
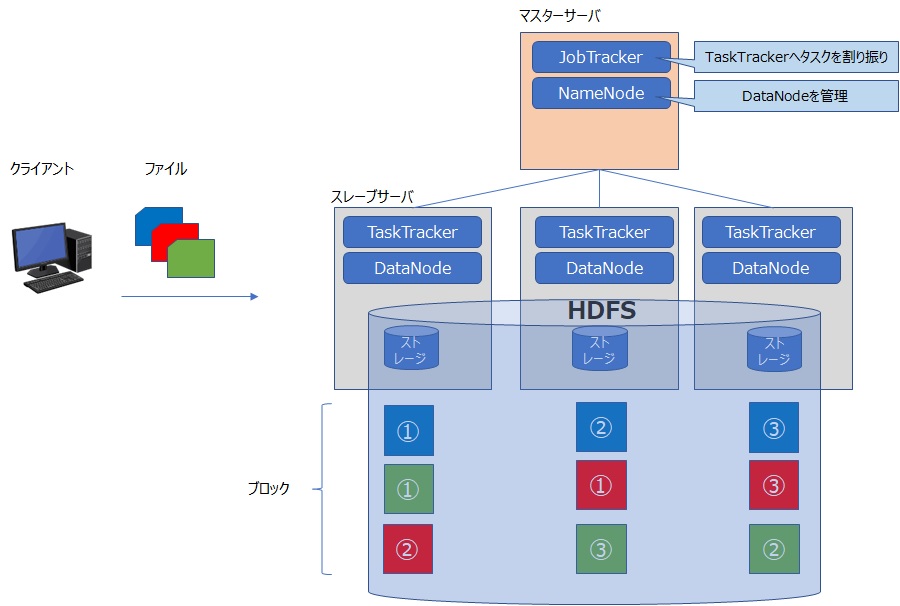
前者の機能である大量データの蓄積(HDFS)では、Hadoop設定がされたサーバ群で一つのファイルシステムを構築し、大量のデータを扱えるようにします。
これは分散ファイルシステム=HDFS(Hadoop Distributed File System)と呼びます。
後者の機能である並列分散処理では、MapRedudeと呼ばれる技術を使い、複数のコンピュータによる並列処理によって、高速処理を実現させるため、並列分散処理と呼びます。
HDFSの観点では、マスターノードであるNameNode、スレーブノードであるDataNodeという関係を築き、構成を組みます。
NameNodeはDataNodeを管理するためのメタ情報を格納します。
DataNodeはデータの実体を保存します。
ファイルを一定サイズで分割したデータをブロックとして扱い、DataNodeへ分散して保存させます。
あるDataNodeが故障しても、複数のDataNodeにブロックのレプリカ(複製)を保存しているので、データの欠損を防ぐ仕組みを備えています。
後者の観点では、マスターノードをJobTrackerとし、スレーブノードをTaskTrackerという関係を築き、構成を組みます。
JobTrackerがTaskTrackerを管理し、TaskTrackerへのタスクの割り当て、リソース管理の管理をします。
TaskTracekrはタスクの実行を行います。
こちらもあるTaskTrackerが故障しても、タスクを別のTaskTrackerへ割り当てなおすので、処理を継続して実行することが可能になっています。
Hadoop2系
次にHadoop2系についてです。
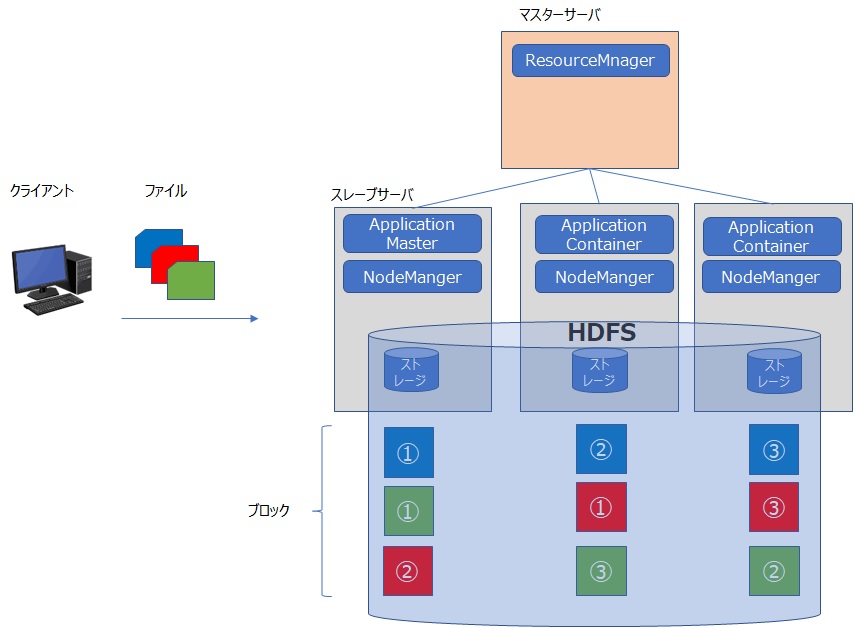
Hadoop1系におけるMapRedudeの仕組みに変更が加わり、YARNという技術を使うようになりました。
仕組みとして、JobTrackerとTaskTrackerがなくなりました。
YARNにより、アプリケーションの集中管理によるマスターノードのボトルネックが解消され、より多数の処理ノードによりHadoopクラスタを構成することが可能になりました。
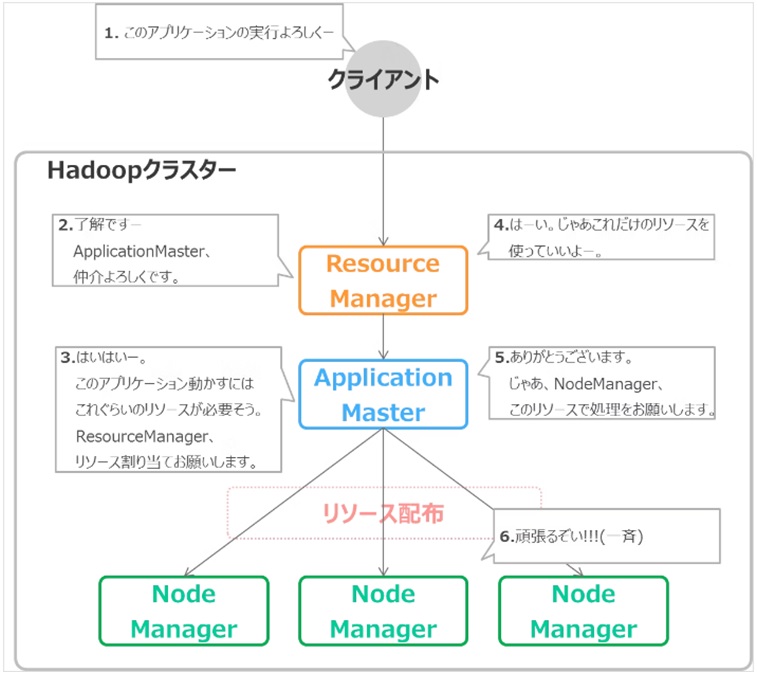
YARNは計算機リソースの管理を行うためのソフトウェア(リソースマネージャ)であり、マスターノードをResourceManager、スレーブをNodeManagerとします。
Hadoopクラスタ内のリソースを管理するマスタノードにはResourceManagerがあり、処理ノードを管理するスレーブノードにNodeManagerで構成されます。
さらにアプリケーションを管理するノードとしてApplicationMasterが存在し、リソース状況を確認しつつ処理を実行するContainer(コンテナ)の確保をResourceManagerに要求します。
ResourceManagerは、NodeManagerからのリソース利用状況を確認して、どのノードでContainerを起動するか、NodeManagerに指示します。
これによって、ApplicationMasterは処理ノードでコンテナ起動を要求して、アプリケーションを実行します。
Hadoop3系
現在、Hadoopは3系になっています。
Hadoop3系では、大きく仕組みが変更されたというより、新しい機能が追加されていっているという感じです。
Erasure Codingがその一つで、より効率的にデータを保存し、データ使用量を減らすことができる機能になります。
Hadoopのエコシステムについて
Hadoopを構成するソフトウェア、もしくは周辺の各種ソフトウェアのことをエコシステムという言い方をします。
各ソフトウェアをコンポーネントという言い方をしていることもあります。
Hadoopを利用する際には、要件応じてエコシステムを扱っていきます。
HBase、Hive、Spark、ZooKeeperなどがあります。
MapReduce以外の分散処理フレームワークとして、Storm、Spark、Tez/Impalaなどが使えるようになりました。

Apache HBase は HDFS や Alluxio の上で動作する NoSQL のキー/バリューストアです。
データには、構造化データと非構造化データがありますが、HBaseは後者のデータを得意としています。
HBase は低レイテンシーで、シェルコマンド、Java API、Thrift、または REST を介してアクセスできます。
Apache Hiveは、MapReduceのバッチジョブをクエリするために、HiveQL(またはHQL)と呼ばれるSQLライクな言語を使用しています。
Hive は INSERT/DELETE/UPDATE/MERGE ステートメントのような ACID トランザクションもサポートしています。
Apache Sparkは、Spark SQLを含み、Spark Streaming(ストリーム処理)、MLlib(機械学習処理)、Graph X(グラフ処理)の4つのコンポーネントで構成される。
クラスタマネージャとして、独自クラスタマネージャのほかに、Hadoop YARN、Apache Mesosを利用することが可能で、YARNと連携してHadoop上で動作することができます。
Hadoopの環境で、より高速な処理を実現させるため、データの格納場所をハードディスク(HDDもしくはSSD)上ではなく、メモリ上で処理する方法を取り入れています。
ZooKeeperは、分散アプリケーション向けの高パフォーマンスなオーケストラサービス。
同期、 設定管理、グルーピング、名前管理、などの機能を提供する。
ビッグデータ分析におけるサービス
Hadoopがビッグデータ分析に利用するためのソフトウェアであることを記載しましたが、
ビックデータ分析分野では、既に以下のように様々なソフトウェアやクラウドサービスが提供されています。
Hadoopは歴史的には古いソフトウェアであり、現在では様々なサービスが世に生み出されています。
・AWS EMR(マネージドで使えるHadoop)
・AWS Redshift
・AWS S3
・Azure SQL Data Warehouse
・GCP BigQuery
・Snowflake
・Splunk
・Databricks
・Oracle Autonomous Data Warehouse
・CDH (Cloudera’s Distribution of Apache Hadoop)
※CDHはHadoop製品を利用している企業をサポートできるように商用化して提供している製品です。
OSSは基本的に自分達でエラー対処等をしていかなければなりませんが、技術的に不安な場合は企業のサポートが得られる商用化された製品を使うことで様々なメリットを享受できます。
もちろん、ライセンス料等の支払で、その分コスト増にはなります。
クラウドを利用するとデータが肥大化してもデータ容量の拡張が容易のため、便利ですが、その反面、コストが増え続ける懸念があります。
また、データ分析基盤であるサーバ(=ノード)を増やして処理効率を上げれば、サーバ利用料も増大していきます。
まずはビックデータ分析の知見を蓄積するため、低コスト運用、トライアルを考慮して、AWS EMRによるスモールスタートもあれば、自社でデータ等を管理するため、OSSのHadoopをオンプレ環境に導入するなどの考えもあるでしょう。
ビッグデータ分析における用語
ビッグデータの世界では、構造化データ、非構造化データ、データレイク、データウェアハウス(DWH)、データマート、データカタログ、データリネージュ、ETLといった用語が登場します。
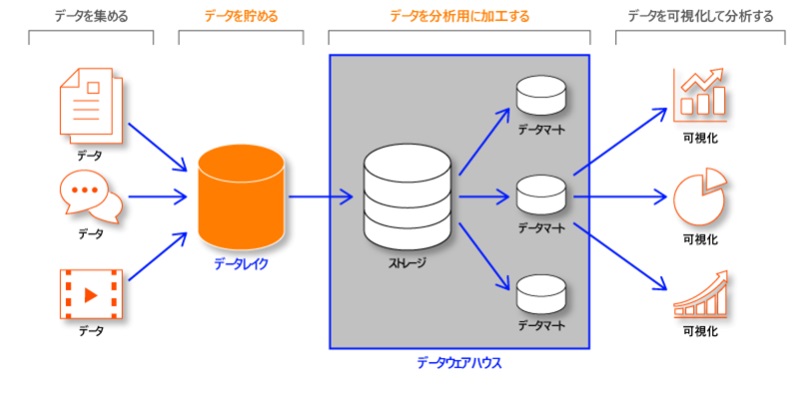
データレイクとは、データの形式を問わず、加工前の様々な生データ(構造化、半構造化、非構造化)を格納する箇所のことを指します。
データウェアハウス(DWH)は、特定の目的のために、加工された構造化データを格納する場所になります。
データレイクにデータを蓄積し、データレイクから扱いやすいデータに加工したものをデータウェアハウスに格納、そこからさらに分析に特化したデータマートを作成するため、ETLを行う。
すぐに用途に応じたデータをみつけるためにデータカタログ化をおこなっておく
といった流れがよくある流れになります。
構造化データ、半構造化データ、非構造化データ
また構造化データ、半構造化データ、非構造化データということが出てきました。
半構造化データは、非構造化データと解釈して記載しているサイトなどもあります。
構造化データというのは、よくあるSQLデータベースに格納できる形式のデータになります。
行と列でデータが整形されており、リレーショナルデータベース(RDBMS)で扱えるデータを構造化データといいます。
一方、非構造化データというのは、特定の構造をとっていないデータのことで、
ドキュメント、テキストデータ、画像、動画、音声、電子メールなどのデータのことを言います。
そして半構造化データというのは、ほぼデータ構造が固定されているようなCSV形式やApache HTTPのaccess log、Jsonファイルなどの形式をもったデータのことを指します。
ORC、Parquet、Avroなどのファイルがあり、これらは半構造化データになります。
各ファイルは、以下のようにデータの構造が異なっています。
・CSV、JSON:テキストフォーマット
・Avro:行指向フォーマット
・ORC、Paquet:列指向(カラムナ)フォーマット
CSVやJSONといったテキストフォーマットは、人間からの可視性が高い、アプリケーション連携がやりやすいというメリットがあります。
しかしながら、データベース用途のフォーマットとしては、人間からの可視性よりも、保存時の圧縮効率や機械による処理のしやすさを追求する必要があります。
データベース用途に向いているフォーマットの種類としては、行指向フォーマットと列指向フォーマットがあります。
行指向フォーマットと列指向フォーマットの違いは、データの格納方式です。
行指向フォーマットは、行方向に連続してデータを格納するため、一つの行をまとめて操作することの多いOLTP処理(オンライントランザクション処理)に向いています。
従来のデータベースは、この行指向フォーマットが利用されてきました。
ストレージ技術などの発展により、DWH用途として、注目されるようになったのが列指向フォーマットです。
列指向フォーマットは、列方向に連続してデータを格納する方式で、列単位でデータを取り出すため、分析に向いています。
これらの処理はOLAP処理(オンライン分析処理)といいます。
このような半構造化データは、NoSQLと呼ばれるデータベースのApache Cassandra、DynamoDBで扱うことができます。
また、DWHであるSnowflake、Redshiftなどでも扱います。
データマート、データカタログなど
データマートとは、データベースのテーブルのデータを加工して、目的・必要な範囲に絞ったテーブルのデータになります。
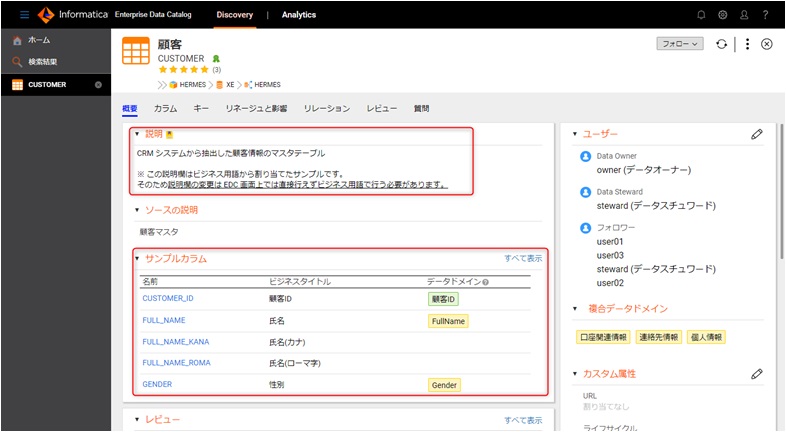
データカタログは、データに関する情報を集約し、一元化して管理するためのデータの目録やカタログです。
メタデータ(データのためのデータ)と呼ばれるものを扱います。
例えば、あるRDBのテーブルに様々なデータがあったら、そのデータが何のためのデータであり、どのようなデータを扱っているかの概要を
まとめたもの=カタログになります。
これをメタデータと言っています。
AWS Glue Data CatalogやInformatica Enterprise Data Catalogが有名どころでしょうか。
膨大なデータから、目的のデータを見つけるのは大変です。
なので、データのカタログをつくって検索できるようにしたり、目的のデータがどの程度有効利用できたのか評価したりすることもできます。
ただ、Informaticaはライセンス使用料が高かったり、様々な機能と操作を駆使する必要があるため、導入には敷居があると思います。
データリネージュは、データが加工されるまでの過程・流れを追跡できるように可視化する機能です。
これもAWS Glue、Informaticaに搭載されています。
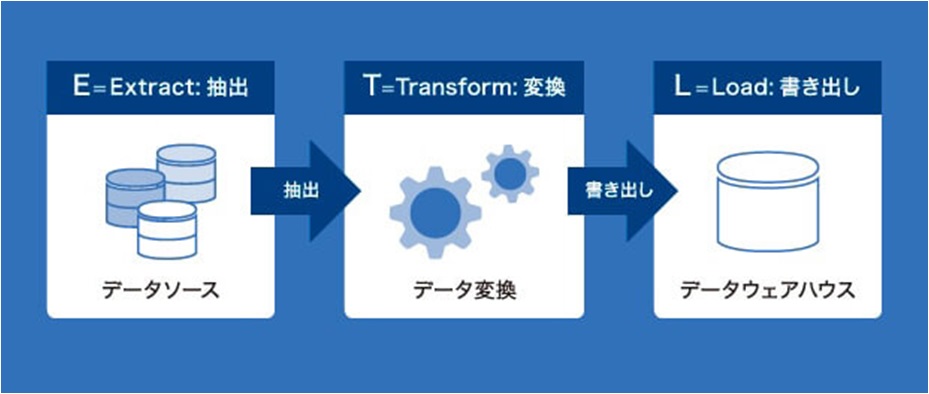
ETLとは、「Extract (抽出)」「Transform (変換)」「Load (書き出し)」の略語になります。
ビックデータ分析では、データを抽出したり、データを加工、変換、データをマート化することからETLという言葉がよく登場します。
このようにビッグデータ分析では、データを扱うための様々なソフトウェアや機能、キーワードが登場します。
SQL(RDBMS)とNoSQL、NewSQL
SQL(RDBMS)
ビッグデータの分析をしているとSQL(RDBMS)とNoSQLワードを耳にするようになります。
NoSQLというのは、RDBMSでは対応が難しい部分に着目されて登場したデータベースになります。
SQL(RDBMS)は「ACID特性」に基づいて設計されており、データの一貫性が保証されています。
これは、正常に処理された場合その結果を表示し、正しく処理されなかった場合は処理される前の状態が表示されることが保証されます。
データはSQL操作にて、テーブル同士を結合して検索するなどの操作が可能です。
SQL(RDBMS)のデメリットは、「分散管理時にデータの書き込みが分散できない」「データが大規模になると処理速度が落ちる」点があります。
複数のサーバーに分散させてデータを管理した場合、読取りは複数のサーバーで同時に読取りできますが、書込み時は一貫性を保つためにデータの整合性をあわせる必要があり、分散しての並列処理ができません。
そのため、同一データに対して一斉に更新処理がかかった場合、処理速度が落ちるというデメリットがあります。
NoSQL
次にNoSQLについてです。
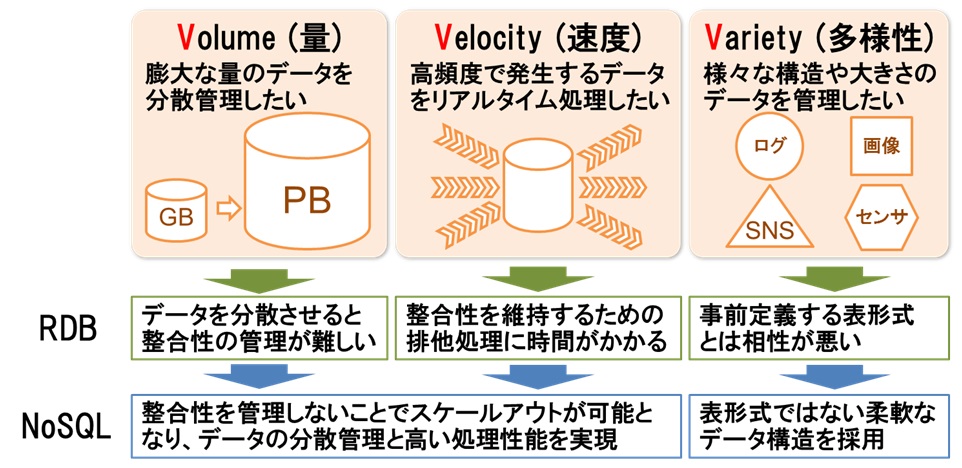
ビッグデータやクラウドなど大容量データを扱う場合、RDBMSでは処理速度の低下が課題となってきました。
NoSQLは、RDBMSのデメリットを解決する機能が備わっています。
NoSQLのメリットとして、まず挙げられるのが、処理速度の速さです。
NoSQLは、データの一貫性を保証しませんが、大容量データでも高速に処理できます。
サーバーの台数を増やし水平分散によるスケールアップが可能なことから、拡張性においても優れています。
NoSQLのデメリットは、データの一貫性が保証されていないため、データの更新や削除処理が頻繁に発生すると、データの整合性が保証されない場合があります。
NoSQLはSQLを使用しないため、複雑な検索はできません。
単純なデータを高速で登録および読み取りは得意ですが、複雑な処理は不向きです。
NoSQLはリレーショナルデータベースではないので、キーを使ってリレーションを結ぶjoinなどの処理ができません。
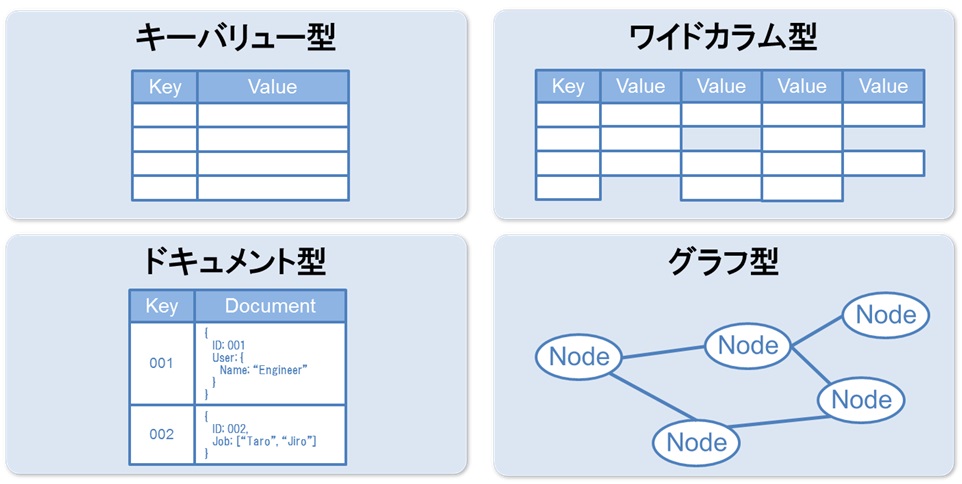
NoSQLでは、以下のようなデータモデルを扱います。
| データ構造 | 概要 | DBの種類 |
| キーバリュー型 | キーとバリューのみのシンプルな組み合わせのモデル | Redis |
| カラム指向型 | キーバリュー型にカラムの概念をもたせたモデル | Cassandra、HBase |
| ドキュメント指向型 | JSONやXML形式で記述されたドキュメントの形で管理するモデル | MongoDB、Couchbase |
| グラフ指向型 | データとデータ間のつながりを管理するモデル | Neo4j、JanusGraph |
NewSQL
SQL(RDBMS)、NoSQLがありますが、最近ではその両方の良いとこどりをしていこうというNewSQLという存在も出てきています。
SQL(RDBMS)のトランザクション性と整合性を保持しつつ、NoSQLの特性である分散型システムのスケーラビリティとパフォーマンスを兼ね備えた新しいデータベースになります。
TiDB、CokroachDB、YugabyteDB、Cloud Spannerなんかが、NewSQLにあたります。
データベースはとても奥が深いです。以下のようにランキングが出ているぐらいです。
DB-Engines Ranking
まとめ
・Hadoopは大規模・大量データの蓄積(HDFS)と並列分散処理(MapReduce)による高速なデータ処理ために利用する技術
・Hadoopにはエコシステムと呼ばれる様々なコンポーネントがあり、便利な機能が多数存在する。
・ビッグデータ分析周りには、Hadoop以外にもAWS EMR、Redshift、Snowflakeなど様々なクラウドサービスが存在する
・ビッグデーター分析ではSQL、NoSQLと呼ばれるそれぞれ異なる特性を持つデータベースを扱う
・データの管理をしやすいようにデータカタログ、データリネージュという機能が存在する
ビッグデータ周りについて少し理解を深めていただけたのではないでしょうか。
コメント